![]()
Free ACD300 Exam Files Downloaded Instantly 100% Dumps & Practice Exam
Free Exam Updates ACD300 dumps with test Engine Practice
NEW QUESTION # 22
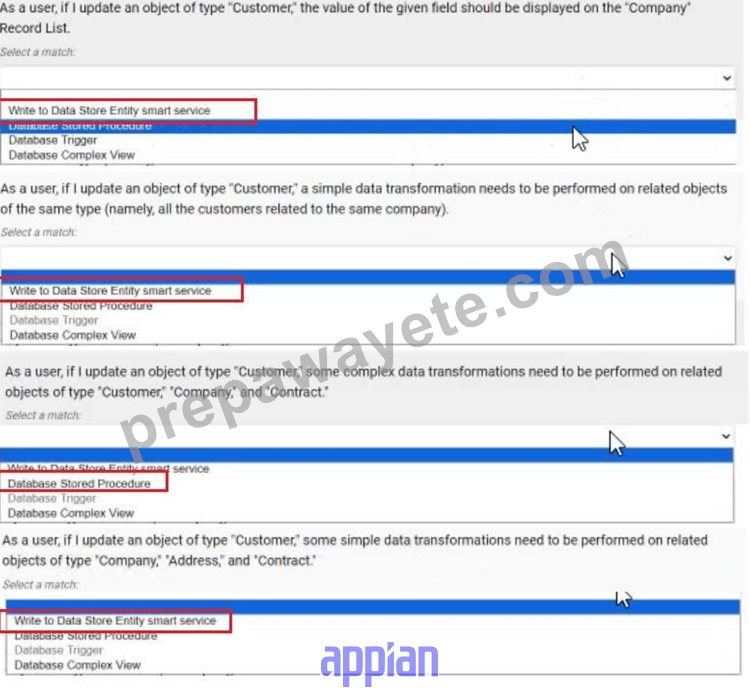
For each scenario outlined, match the best tool to use to meet expectations. Each tool will be used once Note: To change your responses, you may deselected your response by clicking the blank space at the top of the selection list.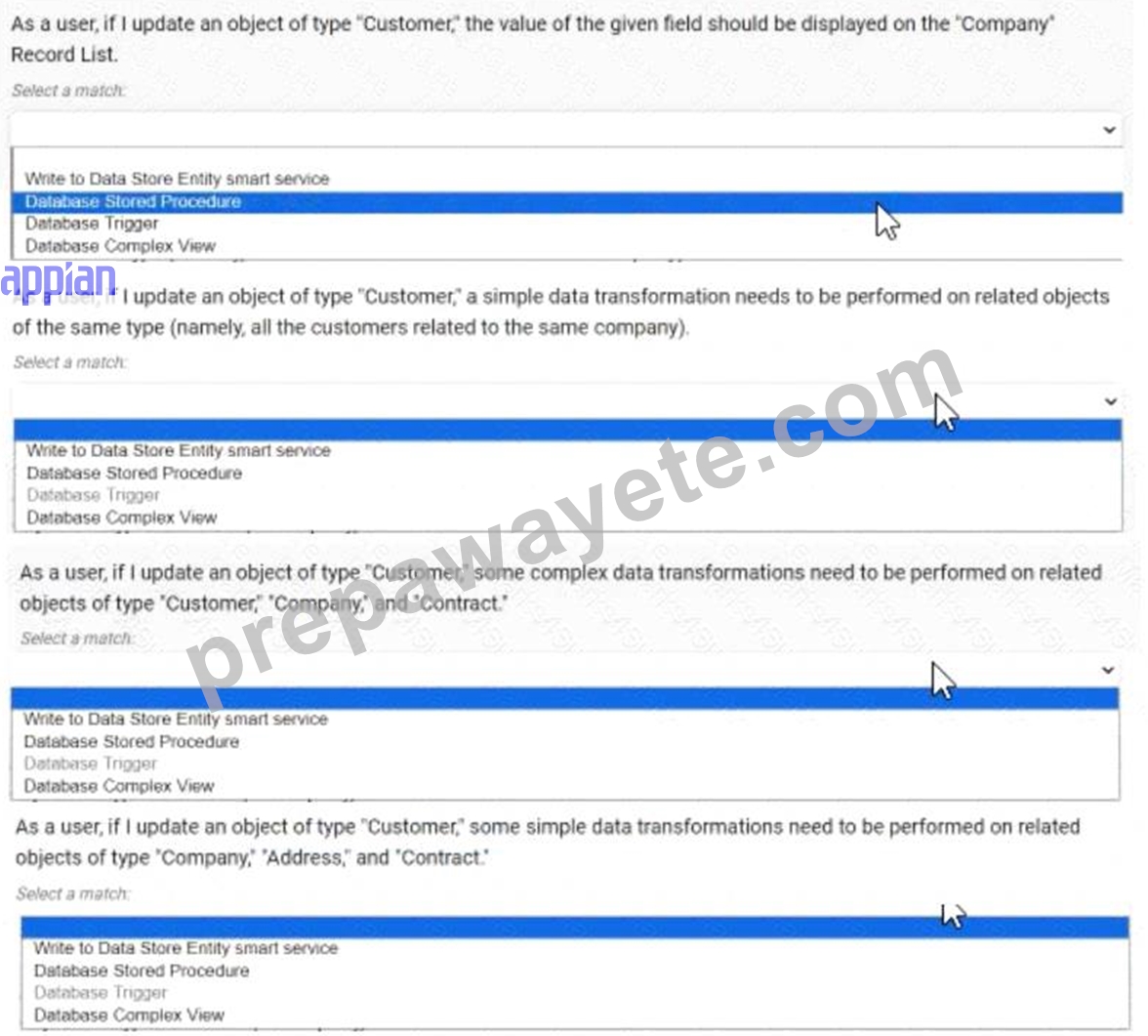
Answer:
Explanation:
NEW QUESTION # 23
You are required to configure a connection so that Jira can inform Appian when specific tickets change (using webhook).
Which three required steps will allow you to connect both systems?
- A. Create an integration object from Applan to Jira to periodically check the ticket status
- B. Create a new API Key and associate a service account
- C. Configure the connection In Jira specifying the URE and credentials
- D. Create a Web API object and set up the correct security.
- E. Give the service account system administrator privileges
Answer: B,C,D
Explanation:
Explanation
The three required steps that will allow you to connect both systems are:
* A. Create a Web API object and set up the correct security. This will allow you to define an endpoint in Appian that can receive requests from Jira via webhook. You will also need to configure the security settings for the Web API object, such as authentication method, allowed origins, and access control.
* B. Configure the connection in Jira specifying the URL and credentials. This will allow you to set up a webhook in Jira that can send requests to Appian when specific tickets change. You will need to specify the URL of the Web API object in Appian, as well as any credentials required for authentication.
* C. Create a new API Key and associate a service account. This will allow you to generate a unique token that can be used for authentication between Jira and Appian. You will also need to create a service account in Appian that has permissions to access or update data related to Jira tickets.
The other options are incorrect for the following reasons:
* D. Give the service account system administrator privileges. This is not required and could pose a security risk, as giving system administrator privileges to a service account could allow it to perform actions that are not related to Jira tickets, such as modifying system settings or accessing sensitive data.
* E. Create an integration object from Appian to Jira to periodically check the ticket status. This is not required and could cause unnecessary overhead, as creating an integration object from Appian to Jira would involve polling Jira for ticket status changes, which could consume more resources than using webhook notifications. Verified References: Appian Documentation, section "Web API" and "API Keys".
NEW QUESTION # 24
Review the following resultof an explain statement: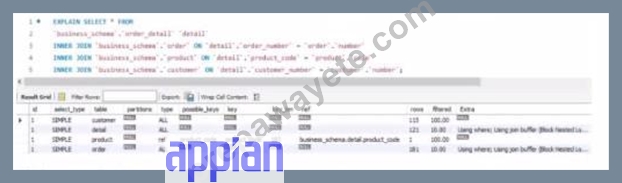
Which two conclusions can you draw from this?
- A. The worst join is the one between the table order_detail and customer
- B. The join between the tables order_detail, order and customerneeds to be tine-tuned due to indices.
- C. The request is good enough to support a high volume of data. but could demonstrate some limitations if the developer queries information related to the product
- D. The join between the tables 0rder_detail and productneeds to be fine-tuned due to Indices
- E. The worst join isthe one between the table order_detail and order.
Answer: A,D
Explanation:
Explanation
* D. The join between the tables order_detail and product needs to be fine-tuned due to Indices. This is correct because the result of the explain statement showsthat the join between these two tables has a high cost of 0.99, which indicates that it is inefficient and needs to be fine-tuned. One possible reason for the high cost is that there are no indices on the columns that are used for joining these two tables, which leads to a full table scan. Therefore, creating indices on these columns could improve the performance of this join.
* E. The worst join is the one between the table order_detail and customer. This is correct because the result of the explain statement shows that the join between these two tables has a very high cost of 1.00, which indicates that it is the worst join in terms of efficiency and needs to be fine-tuned. One possible reason for the high cost is that there are no indices on the columns that are used for joining these two tables, which leads to a full table scan. Therefore, creating indices on these columns could improve the performance of this join.
The other options are incorrect for the following reasons:
* A. The request is good enough to support a high volume of data, but could demonstrate some limitations if the developer queries information related to the product. This is incorrect because the request is not good enough to support a high volume of data, as it has two joins with very high costs that need to be fine-tuned. Moreover, querying information related to the product would not necessarily cause any limitations, as long as the join between order_detail and product is optimized.
* B. The worst join is the one between the table order_detail and order. This is incorrect because the result of the explain statement shows that the join between these two tables has a low cost of 0.01, which indicates that it is efficient and does not need to be fine-tuned.
* C. The join between the tables order_detail, order and customer needs to be fine-tuned due to indices.
This is incorrect because there is no such join between three tables in the result of the explain statement.
There are only two joins: one between order_detail and order, and another between order_detail and customer. Each of these joins needs to be fine-tuned separately due to indices.
NEW QUESTION # 25
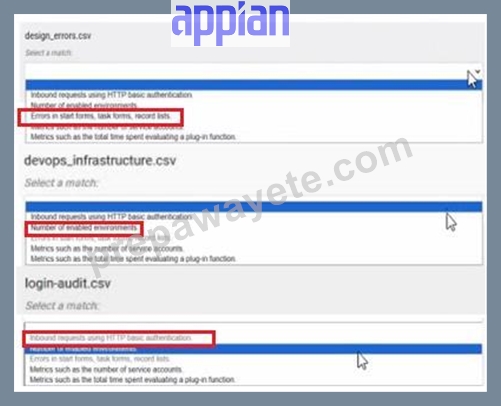
You are reviewing log files that can be accessed in Appian to monitor and troubleshoot platform-based issues.
For each type of log file, match the corresponding Information that it provides. Each description will either be used once, or not at all.
Note: To change your responses, you may deselect your response by clicking the blank space at the top of the selection list.
Answer:
Explanation:
NEW QUESTION # 26
You are on a protect with an application that has been deployed to Production and is live with users. The client wishes to increase the number of active users.
You need to conduct load testing to ensure Production can handle the increased usage Review the specs for four environments in the following image.
Which environment should you use for load testing7
- A. acmetest
- B. acmedev
- C. acme
- D. acmeuat
Answer: C
Explanation:
Explanation
The best environment to use for load testing is acme, which is the production environment. This is because load testing should be performed on an environment that is as close as possible to the actual production environment, in terms of hardware, software, configuration, data, and user behavior. This way, the results of the load testing will be more realistic and reliable, and can help to identify and resolve any performance issues or bottlenecks before increasing the number of active users. Verified References: Appian Documentation, section "Load Testing".
NEW QUESTION # 27
You add an index on the searched field of a MySQL table with many rows (>100k).
The field would benefit greatly from the Index in which three scenarios?
- A. The Add contains Dig integers, above and below 0.
- B. The field contains a structured JSON.
- C. The field contains long unstructured text such as a hash
- D. The field contains a textual shot Business code.
- E. The field contains many datetimes, covering a large range
Answer: A,D,E
Explanation:
Explanation
The field would benefit greatly from the index in the following scenarios:
* A. The field contains a textual short Business code. This is a scenario where an index can improve the performance of queries that search for exact matches or ranges of values in the field. A textual short Business code is likely to have high cardinality, meaning that it has many distinct values and low duplication. This makes the index more selective and efficient, as it can quickly narrow down the results based on the search criteria.
* C. The field contains many datetimes, covering a large range. This is a scenario where an index can improve the performance of queries that search for exact matches or ranges of values in the field. A datetime field is likely to have high cardinality, meaning that it has many distinct values and low duplication. This makes the index more selective and efficient, as it can quickly narrow down the results based on the search criteria.
* D. The field contains big integers, above and below 0. This is a scenario where an index can improve the performance of queries that search for exact matches or ranges of values in the field. A big integer field is likely to have high cardinality, meaning that it has many distinct values and low duplication. This makes the index more selective and efficient, as it can quickly narrow down the results based on the search criteria.
The other options are incorrect for the following reasons:
* B. The field contains long unstructured text such as a hash. This is a scenario where an index might not improve the performance of queries that search for exact matches or ranges of values in the field. A long unstructured text field is likely to have low cardinality, meaning that it has few distinct values and high duplication. This makes the index less selective and efficient, as it cannot quickly narrow down the results based on the search criteria. Moreover, indexing a long unstructured text field could increase thestorage space and maintenance cost for the database, which could affect the overall performance.
* E. The field contains a structured JSON. This is a scenario where an index might not improve the performance of queries that search for exact matches or ranges of values in the field. A structured JSON field is not a native data type in MySQL, and it requires special functions or operators to access or manipulate its elements. Indexing a structured JSON field could increase the complexity and overhead for the database, which could affect the overall performance. Verified References: Appian Documentation, section "Query Optimization".
NEW QUESTION # 28
Your application contains a process model that Is scheduled to run daily at a certain time, which kicks off a user input task to a specified user on the 1ST time zone for morning data collection The time zone is set to the (default) pm!timezone.
In this situation, what does the pm!tinezone reflect?
- A. The time zone of the user who is completing the input task.
- B. The time zone of the server where Applan is intuited
- C. The line zone of the user who most recently published the process model
- D. The default time zone for the environment as specified in the Administration Console
Answer: D
Explanation:
Explanation
In this situation, pm!timezone reflects the default time zone for the environment as specified in the Administration Console. pm!timezone is a process variable that returns the time zone of the process. If the time zone is not explicitly set in the process model, then pm!timezone returns the default time zone for the environment, which can be configured in the Administration Console. In this case, the time zone is set to the (default) pm!timezone, which means that the process model does not have a specific time zone, and therefore uses the default time zone for the environment.
The other options are not correct. Option A, the time zone of the server where Appian is installed, is not what pm!timezone reflects, as the server time zone may not be the same as the default time zone for the environment. Option B, the time zone of the user who most recently published the process model, is not what pm!timezone reflects, as the user's time zone may not be the same as the default time zone for the environment. Option D, the time zone of the user who is completing the input task, is not what pm!timezone reflects, as the user's time zone may not be the same as the default time zone for the environment.
NEW QUESTION # 29
You have created a Web API in Appian. with the following URL to call it:
https://exampleappiancloud.com/suite/webapi/usef_managefnent/ users ?username=)=john.smith.
Which is the connect syntax forreferring to the user name parameter'
- A. httpirequest.queryParameters users username
- B. httpirequest usees username
- C. httpirequest queryParameters.username
- D. httpirequest formData username
Answer: C
Explanation:
Explanation
The correct syntax for referring to the username parameter in the Web API URL is
httpirequest.queryParameters.username. This syntax allows you to access the value of the username parameter that is passed in the query string of the URL after the question mark (?). For example, if the URL ishttps://exampleappiancloud.com/suite/webapi/user_management/users?username=john.smith, then
httpirequest.queryParameters.username will return john.smith. Verified References: Appian Documentation, section "Web API".
NEW QUESTION # 30
On the latest Health Check report from your Cloud TEST environment utilizing a ManaDB add-on. you note the following findings Category; User Experience Description; # of slow query rules Risk; High Category; User Experience Description: U of slow write to data store nodes Risk: High Which three things might you do to address this, without consulting the business?
- A. Use smaller CDTs or limit the fields selected in alqueryEntity()
- B. Optimize the database execution use standard database performance troubleshooting methods and tools (such as query execution plans)
- C. Reduce the size and complexity of the inputs. If you ore passing in a list, consider whether (he data model can be redesigned lo pass single values instead
- D. Optimize the database execution. Replace the new with a materialized view.
- E. Reduce the batch size for database queues to 10.
Answer: A,B,C
Explanation:
Explanation
The three things that might help to address the findings of the Health Check report are:
* B. Optimize the database execution using standard database performance troubleshooting methods and tools (such as query execution plans). This can help to identify and eliminate any bottlenecks or inefficiencies in the database queries that are causing slow query rules or slow write to data store nodes.
* C. Reduce the size and complexity of the inputs. If you are passing in a list, consider whether the data model can be redesigned to pass single values instead. This can help to reduce the amount of data that needs to be transferred or processed by the database, which can improve the performance and speed of the queries or writes.
* E. Use smaller CDTs or limit the fields selected in a!queryEntity(). This can help to reduce the amount of data that is returned by the queries, which can improve the performance and speed of the rules that
* use them.
The other options are incorrect for the following reasons:
* A. Reduce the batch size for database queues to 10. This might not help to address the findings, as reducing the batch size could increase the number of transactions and overhead for the database, which could worsen the performance and speed of the queries or writes.
* D. Optimize the database execution. Replace the new with a materialized view. This might not help to address the findings, as replacing a view with a materialized view could increase the storage space and maintenance cost for the database, which could affect the performance and speed of the queries or writes. Verified References: Appian Documentation, section "Performance Tuning".
NEW QUESTION # 31
You are planning a strategy around data volume testing for an Appian application that queries and writes to MySQL database.
You have administrator access to the Appian application and to the database.
What are two key considerations when designing a data volume testing strategy?
- A. The amount of data that needs to be populated should be determined by the project sponsor and the stakeholders based on their estimation
- B. large datasets must be loaded via Applan processes
- C. Data model changes must wait until towards the end of the protect.
- D. Testing with the correct amount of data should be in the definition of done as part of each sprint.
- E. Data from previous tests needs to remain in the testing environment prior to loading prepopulated data
Answer: C,D
Explanation:
Explanation
When designing a data volume testing strategy for an Appian application that queries and writes to MySQL database, you should consider two key considerations:
* Testing with the correct amount of data should be in the definition of done as part of each sprint. Data volume testing is a type of testing that verifies how well an application performs when handling large amounts of data. Data volume testing is important to ensure that the application meets the performance and quality requirements of the users and stakeholders. By including data volume testing in the definition of done as part of each sprint, you can ensure that each feature or functionality of your application is tested with realistic data volumes before being delivered to production. This way, you can identify and resolve any potential issues or bottlenecks early in the development cycle, and avoid any surprises or delays later on.
* Data model changes must wait until towards the end of the project. Data model changes are changes that affect the structure or schema of your database, such as adding, modifying, or deleting tables, columns, indexes, or constraints. Data model changes are risky and costly to make, especially when dealing with large amounts of data. Data model changes can affect the performance, functionality, or integrity of your
* application and database. Therefore, data model changes must wait until towards the end of the project, when you have finalized your requirements and design decisions, and have minimized your data volume testing efforts. By waiting until towards the end of the project to make data model changes, you can reduce the impact and complexity of those changes, and avoid any unnecessary rework or regression.
The other options are not as effective. Option A, data from previous tests needs to remain in the testing environment prior to loading prepopulated data, is not a key consideration for designing a data volume testing strategy, but rather a best practice for preparing your testing environment. Option B, large datasets must be loaded via Appian processes, is not a key consideration for designing a data volume testing strategy, but rather a technical implementation detail that may or may not be suitable for your application. Option C, the amount of data that needs to be populated should be determined by the project sponsor and the stakeholders based on their estimation, is not a key consideration for designing a data volume testing strategy, but rather an input or assumption that you need to validate before conducting your data volume testing.
NEW QUESTION # 32
You are reviewing the Engine Performance Logs in Production for a single application thathas been live for six months. This application experiences concurrent user activity and has a fairly sustained load during business hours. The client has reported performance issues with the application during business hours.
During your investigation, you notice a high Work Queue - Java Work Queue Size value in the logs You also notice unattended process activities, including timer events and sending notifications emails, are taking far longer to execute than normal.
The client Increased the number of CPU cores prior to the application going live What is the next recommendation?
- A. Add more application servers.
- B. Optimize slow-performing user interfaces.
- C. Add execution and analytics shards
- D. Add more engine replicas.
Answer: D
Explanation:
Explanation
Adding more engine replicas will increase the number of threads available to execute unattended process activities, such as timer events and sending notification emails. This will reduce the Java Work Queue Size and improve the performance of the application. Verified References: Appian Engine Performance Logs, Appian Engine Configuration
NEW QUESTION # 33
You are just starting with a new team that has been working together on an application for months. They ask you toreview some of their views thathave been degrading inperformance. The viewsare highly complex with hundreds of lines of SOL What is the first step in troubleshooting the degradation?
- A. Run an explain statement on the views, identify criticalareas of improvement that can be remediated and without business knowledge
- B. Go through the entire database structure to obtain on overview, ensure you understand the business needs, andthen normalize the tables to optimizeperformance.
- C. Go through all of the tables one by one to identify which of the grouped by. ordered by. or joined keys are currently indexed
- D. Browse through the tables, note any tables that contain a large volume of null values, and work with your team to plan for table restructure.
Answer: A
Explanation:
Explanation
The first step in troubleshooting the degradation of the views is to run an explain statement on the views, identify critical areas of improvement that can be remediated without business knowledge. An explain statement is a tool that shows how a database executes a query or a view, and provides information about the cost, plan, and steps involved in the execution. By running an explain statement on the views, you can identify any inefficiencies or bottlenecks that are causing the degradation, such as missing indices, full table scans, nested loops, or hash joins. You can then apply some basic optimization techniques that do not require business knowledge, such as creating indices, limiting the number of columns or rows returned, using joins instead of subqueries, or using materialized views. Verified References: Appian Documentation, section
"Query Optimization".
NEW QUESTION # 34
You are the lead developer for an Appian project, in a backlog refinement meeting You are presented with the following user story.
As a restaurant customer. I need to be able to place my food order online to avoid waiting in line for take out.' Which two functional acceptance criteria would you consider 'good'?
- A. The user will receive an email notification when their order is completed.
- B. The system mutt handle up to 500 unique orders per day
- C. The user will click Save, and the order information will be saved in the ORDER table and have audit history
- D. The user cannot submit the form without filling out all required fields.
Answer: A,D
Explanation:
Explanation
Functional acceptance criteria are the conditions that a user story must satisfy to be accepted by the user or stakeholder. They should be specific, measurable, achievable, relevant, and testable. In this case, two functional acceptance criteria that would be considered 'good' are:
* The user will receive an email notification when their order is completed. This is a specific, measurable, achievable, relevant, and testable criterion that describes a feature that the user needs to be informed of their order status.
* The user cannot submit the form without filling out all required fields. This is a specific, measurable, achievable, relevant, and testable criterion that describes afeature that the user needs to provide valid and complete information for their order.
The other options are not as good. Option A, the user will click Save, and the order information will be saved in the ORDER table and have audit history, is not a functional acceptance criterion, but rather a technical implementation detail that is not relevant or visible to the user. Option C, the system must handle up to 500 unique orders per day, is not a functional acceptance criterion, but rather a non-functional requirement that describes a performance or quality attribute of the system.
NEW QUESTION # 35
What are two advantages of having High Availability (HA) for Applan Cloud applications?
- A. An Applan Cloud HA instance is composed of multiple active nodes running in different availability zones in differentregions.
- B. In the event of a system failure, your Appian instance will fie restored and available to your users in less than 15 minutes.having lost no more than the last 1minute worth of data.
- C. Data andtransactions are continuouslyreplicated across the active nodes to achieve redundancy and avoid single points offailure.
- D. A typical Appian Cloud HA instance is composed of two active nodes.
Answer: B,C
Explanation:
Explanation
The two advantages of having High Availability (HA) for Appian Cloud applications are:
* B. Data and transactions are continuously replicated across the active nodes to achieve redundancy and avoid single points of failure. This is an advantage of having HA, as it ensures that there is always a backup copy of data and transactions in case one of the nodes fails or becomes unavailable. This also improves data integrity and consistency across the nodes, as any changes made to one node are automatically propagated to the other node.
* D. In the event of a system failure, your Appian instance will be restored and available to your users in less than 15 minutes, having lost no more than the last 1 minute worth of data. This is an advantage of having HA, as it guarantees a high level of service availability and reliability for your Appian instance.
If one of the nodes fails or becomes unavailable, the other node will take over and continue to serve requests without any noticeable downtime or data loss for your users.
The other options are incorrect for the following reasons:
* A. An Appian Cloud HA instance is composed of multiple active nodes running in different availability zones in different regions. This is not an advantage of having HA, but rather a description of how HA works in Appian Cloud. An Appian Cloud HA instanceconsists of two active nodes running in different availability zones within the same region, not different regions.
* C. A typical Appian Cloud HA instance is composed of two active nodes. This is not an advantage of having HA, but rather a description of how HA works in Appian Cloud. A typical Appian Cloud HA instance consists of two active nodes running in different availability zones within the same region, but this does not necessarily provide any benefit over having one active node. Verified References: Appian Documentation, section "High Availability".
NEW QUESTION # 36
Your clients customer management application is finally released lo Production. After a few weeks of small enhancements and patches, the client Is ready to build their next application. The new application will leverage customer information from the first application to allow the client to launch targeted campaigns for select customers in order to increase sales.As part of the first application, your team had built a section lo display key customer information such as their name, address, phone number, how long they have been a customer, etc. A similar section will be needed on the campaign record you are building.
One of your developers shows you the new object they are working on for the new application and asks you to review it as they are running Into a few issues.
What feedback should you give?
- A. Ask the developer to convert the original customer section into a shared object so it can be used by the new application
- B. Create a duplicate version of that sect<on designed for the campaign record.
- C. Point the developer to the relevant areas in the documentation or Applan Community where they can find more Information on the issues they are running into.
- D. Provide guidance to the developer on how to address the issues so that they can proceed with their work
Answer: A
Explanation:
Explanation
The best practice for reusing common UI components across multiple applications is to create shared objects, which are objects that can be referenced by other applications without being copied or duplicated. This way, any changes made to the shared object will be reflected in all applications that use it, ensuring consistency and maintainability. Therefore, instead of creating a duplicate version of the customer section for the new application, the developer should convert the original customer section into a shared object and reference it from both applications. Verified References: Appian Documentation, section "Shared Objects".
NEW QUESTION # 37
......
Provide Valid Dumps To Help You Prepare For Appian Certified Lead Developer Exam: https://www.prepawayete.com/Appian/ACD300-practice-exam-dumps.html
Updated Verified ACD300 dumps Q&As - 100% Pass Guaranteed: https://drive.google.com/open?id=17iw8qj_qLz8-EJDjCuu3525LlJ1gEIlR